Многомерный подход к представлению данных в базах был разработан практически в одно время с реляционным, но многомерных СУБД (МСУБД), которые бы реально работали, долгое время было очень мало. Только с середины 1990-х гг. к ним стал возникать массовый интерес.
Толчком к тому была статья, которую написал в 1993 г. один из основоположников реляционного подхода Э. Кодд. В статье он сформулировал основные требования к системам оперативной аналитической обработки, самые важные из которых относились к возможностям концептуального представления и обработки многомерных данных. Многомерные системы предоставляют возможность оперативной обработки информации для проведения анализа и принятия решения.
Информационные системы (ИС) развивались в двух направлениях:
- системы аналитической обработки (системы поддержки принятия решений);
- системы оперативной (транзакционной) обработки.
В системах аналитической обработки реляционные СУБД были недостаточно гибкими. Они были предназначены для информационных систем оперативной обработки информации и являлись в этой области достаточно эффективными.
Более эффективными в системах аналитической обработки оказались многомерные системы управления БД.
Многомерные СУБД – это узкоспециализированные СУБД, которые предназначены для интерактивной аналитической обработки информации.
Основные понятия
Основными понятиями, которые используются в МСУБД, являются агрегируемость, историчность и прогнозируемость данных. Рассмотрим эти понятия.
Под агрегируемостъю данных подразумевается ознакомление с информацией на разных уровнях ее обобщения.
В ИС степень детальности представления данных зависит от уровня пользователя: руководитель, управляющий, оператор, аналитик.
Историчность данных подразумевает обеспечение высокого уровня неизменности (статичности) самих данных и их взаимосвязей с обязательной привязкой данных ко времени.
Статичность данных предоставляет возможность использования при их обработке специализированных методов загрузки, индексации, хранения и выборки.
Привязка данных ко времени нужна для частого выполнения запросов, которые имеют значения дата/время в выборке. Необходимость упорядочивания данных по временному показателю при обработке и представлении данных пользователю приводит к необходимости соответствия определенным требованиям к механизмам хранения и доступа к информации. Например, чтобы уменьшить время обработки запросов нужно, чтобы данные были постоянно отсортированы в том порядке, в каком они наиболее часто запрашиваются.
Под прогнозируемостью данных понимают использование функций прогнозирования для разных временных интервалов.
Многомерность модели данных позволяет многомерно представлять логическую структуру информации при ее описании и при выполнении операций манипулирования данными.
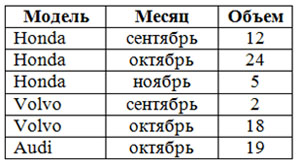
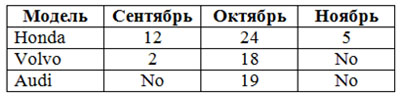
В сравнении с реляционной, многомерная модель имеет более высокую наглядность и информативность. На рисунке 1 представлены реляционная (а) и многомерная (б) модель представления одинаковых данных об объемах продаж автомобилей.
а)
б)
При построении многомерной модели с мерностью более двух не всегда для визуального представления информации используются многомерные объекты (3-х-, 4-х- и больше мерные гиперкубы). Пользователю удобнее пользоваться двухмерными таблицами или графиками. При этом данные представляются в виде «срезов» из многомерной базы данных, которые могут быть выполнены с различной степенью детализации.
В многомерных моделях данных используются следующие основные понятия:
Измерение – множество однотипных данных, которые образуют одну грань гиперкуба.
Чаще всего используются:
- временные измерения: Год, Квартал, Месяц, День;
- географические измерения: Город, Район, Регион, Страна и т.д.
Измерения в многомерной модели данных выступают в роли индексов, которые служат для идентификации конкретных значений в ячейках гиперкуба.
Ячейка – поле, которое содержит значение, однозначно определяющееся фиксированным набором измерений.
Поле чаще всего имеет цифровой тип. Ячейки в качестве значений могут содержать переменные (значения могут изменяться и их можно загрузить из внешнего источника данных или сформировать программно) или формулы (значения, которые вычисляются согласно заданным формулам).
На рисунке 1 каждая ячейка Объем продаж однозначно определена комбинацией измерений Месяц и Модель. В практическом применении часто необходимо большее число измерений. На рисунке 2 представлен пример трехмерной модели данных.
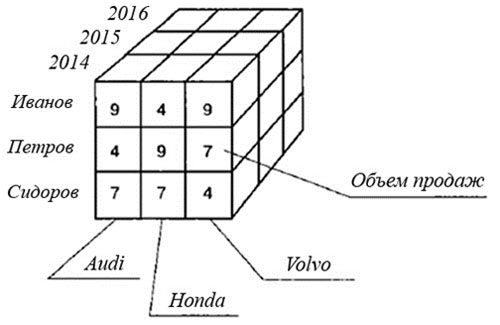
Измерения:
Время (год) – 2014, 2015, 2016
Менеджер – Иванов, Петров, Сидоров
Модель – Honda, Volvo, Audi
Показатель: Объем продаж
Схемы организации данных
В МСУБД существует 2 основные схемы организации данных: гиперкубическая и поликубическая.
Гиперкубическая схема предполагает использование показателей, все из которых определены одним и тем же набором измерений.
Другими словами, если БД содержит несколько гиперкубов, то все они одинаковой размерности и с совпадающими измерениями. Очевидным является то, что в некоторых случаях БД может содержать избыточную информацию (в случае обязательного заполнения ячеек).
Поликубическая схема предполагает наличие в БД нескольких гиперкубов с разной размерностью и разными измерениями в качестве граней.
Сервер Oracle Express Server является системой, которая поддерживает поликубическую схему БД.
Преимущества и недостатки многомерной модели
Основное преимущество использования многомерной модели данных состоит в удобстве и эффективности аналитической обработки больших объемов данных, которые связаны со временем.
Среди недостатков многомерной модели данных выделяют ее громоздкость для решения простейших задач обычной оперативной обработки информации.
Системы, которые поддерживают многомерные модели данных: Cache, Oracle Express Server, Media Multi-matrix и Essbase.
 Найти эксперта
Найти эксперта