




 Найти эксперта
Найти эксперта



Чаще всего кодированию подвергаются тексты, написанные на естественных языках (русском, немецком и др.).
Основные способы кодирования текстовой информации
Существует несколько основных способов кодирования текстовой информации:
- графический, в котором текстовая информация кодируется путем использования специальных рисунков или знаков;
- символьный, в котором тексты кодируются с использованием символов того же алфавита, на котором написан исходник;
- числовой, в котором текстовая информация кодируется с помощью чисел.
Процесс чтения текста представляет собой процесс, обратный его написанию, в результате которого письменный текст преобразуется в устную речь. Чтение – это ничто иное, как декодирование письменного текста.
А сейчас обратите внимание на то, что существует много способов кодирования одного и того же текста на одном и том же языке.
Поскольку мы русские, то и текст привыкли записывать с помощью алфавита своего родного языка. Однако тот же самый текст можно записать, используя латинские буквы. Иногда это приходится делать, когда мы отправляем SMS по мобильному телефону, клавиатура которого не содержит русских букв, или же электронное письмо на русском языке за границу, если у адресата нет русифицированного программного обеспечения. Например, фразу «Здравствуй, дорогой Саша!» можно записать как: «Zdravstvui, dorogoi Sasha!».
Стенография
Стенография — это один из способов кодирования текстовой информации с помощью специальных знаков. Она представляет собой быстрый способ записи устной речи. Навыками стенографии могут владеть далеко не все, а лишь немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст синхронно с речью выступающего человека, что, на наш взгляд, достаточно сложно. Однако для них это не проблема, поскольку в стенограмме целое слово или сочетание букв могут обозначаться одним знаком. Скорость стенографического письма превосходит скорость обычного в $4-7$ раз. Расшифровать (декодировать) стенограмму может только сам стенографист.
Найти эксперта
На рисунке представлен пример стенографии, в которой написано следущее: «Говорить умеют все люди на свете. Даже у самых примитивных племен есть речь. Язык — это нечто всеобщее и самое человеческое, что есть на свете»:
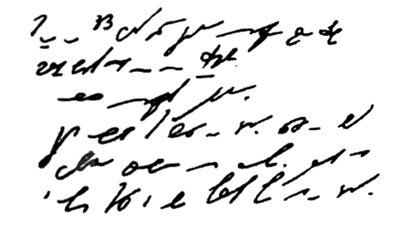
Рисунок 1.
Стенография позволяет не только вести синхронную запись устной речи, но и рационализировать технику письма.
Приведёнными примерами мы проиллюстрировали важное правило: для кодирования одной и той же информации можно использовать разные способы, при этом их выбор будет зависеть от цели кодирования, условий и имеющихся средств.
Если нам нужно записать текст в темпе речи, сделаем это с помощью стенографии; если нужно передать текст за границу, воспользуемся латинским алфавитом; если необходимо представить текст в виде, понятном для грамотного русского человека, запишем его по всем правилам грамматики русского языка.
Также немаловажен выбор способа кодирования информации, который, в свою очередь, может быть связан с предполагаемым способом её обработки.
Рассмотрим пример представления чисел количественной информации. Используя буквы русского алфавита, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, запишем: $35$. Допустим нам необходимо произвести вычисления. Естественно, что для выполнения расчётов мы выберем удобную для нас запись числа арабскими цифрами, хотя можно примеры описывать и словами, но это будет довольно громоздко и не практично.
Заметим, что приведенные выше записи одного и того же числа используют разные языки: первая — естественный русский язык, вторая — формальный язык математики, не имеющий национальной принадлежности. Переход от представления на естественном языке к представлению на формальном языке можно также рассматривать как кодирование.
Криптография
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью.
Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука криптография.
Криптография — это наука о методах и принципах передачи и приема зашифрованной с помощью специальных ключей информации. Ключ — секретная информация, используемая криптографическим алгоритмом при шифровании/расшифровке сообщений.
Числовое кодирование текстовой информации
В каждом национальном языке имеется свой алфавит, который состоит из определенного набора букв, следующих друг за другом, а значит и имеющих свой порядковый номер.
Каждой букве сопоставляется целое положительное число, которое называют кодом символа. Именно этот код и будет хранить память компьютера, а при выводе на экран или бумагу преобразовывать в соответствующий ему символ. Помимо кодов самих символов в памяти компьютера хранится и информация о том, какие именно данные закодированы в конкретной области памяти. Это необходимо для различия представленной информации в памяти компьютера (числа и символы).
Используя соответствия букв алфавита с их числовыми кодами, можно сформировать специальные таблицы кодирования. Иначе можно сказать, что символы конкретного алфавита имеют свои числовые коды в соответствии с определенной таблицей кодирования.
Однако, как известно, алфавитов в мире большое множество (английский, русский, китайский и др.). Соответственно возникает вопрос, каким образом можно закодировать все используемые на компьютере алфавиты.
Чтобы ответить на данный вопрос, нам придется заглянуть назад в прошлое.
В $60$-х годах прошлого века в американском национальном институте стандартизации (ANSI) была разработана специальная таблица кодирования символов, которая затем стала использоваться во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange, что означает в переводе с английского «американский стандартный код для обмена информацией»).
В данной таблице представлен $7$-битный стандарт кодирования, при использовании которого компьютер может записать каждый символ в одну $7$-битную ячейку запоминающего устройства. При этом известно, что в ячейке, состоящей из $7$ битов, можно сохранять $128$ различных состояний. В стандарте ASCII каждому из этих $128$ состояний соответствует какая-то буква, знак препинания или же специальный символ.
В процессе развития вычислительной техники стало ясно, что $7$-битный стандарт кодирования достаточно мал, поскольку в $128$ состояниях $7$-битной ячейки нельзя закодировать буквы всех письменностей, имеющихся в мире.
Чтобы решить эту проблему, разработчики программного обеспечения начали создавать собственные 8-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до $256$ символов. Во избежание путаницы, первые $128$ символов в таких кодировках, как правило, соответствуют стандарту ASCII. Оставшиеся $128$ - реализуют региональные языковые особенности.
Как мы знаем национальных алфавитов огромное количество, поэтому и расширенные таблицы ASCII-кодов представлены множеством вариантов. Так для русского языка существует также несколько вариантов, наиболее распространенные Windows-$1251$ и Koi8-r. Большое количество вариантов кодировочных таблиц создает определенные трудности. К примеру, мы отправляем письмо, представленное в одной кодировке, а получатель при этом пытается прочесть его в другой. В результате на экране у него появляется непонятная абракадабра, что говорит о том, что получателю для прочтения письма требуется применить иную кодировочную таблицу.
Существует и другая проблема, которая заключается в том, что алфавиты некоторых языков содержат слишком много символов, которые не позволяют помещаться им в отведенные позиции с $128$ до $255$ однобайтовой кодировки.
Следующая проблема возникает тогда, когда в тексте используют несколько языков (например, русский, английский и немецкий). Нельзя же использовать обе таблицы сразу.
Для решения этих проблем в начале $90$-х годов прошлого столетия был разработан новый стандарт кодирования символов, который назвали Unicode. С помощью этого стандарта стало возможным использование в одном тексте любых языков и символов.
Данный стандарт для кодирования символов предоставляет $31$ бит, что составляет $4$ байта за минусом $1$ бита. Количество возможных комбинаций при использовании данной кодировочной таблицы очень велико: $231 = 2 \ 147 \ 483 \ 684$ (т.е. более $2$ млрд.). Это возможно стало в связи с тем, что Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и другие специальные символы. И все-таки информационная емкость $31$-битового Unicode слишком велика, И как следствие, наиболее часто используют именно сокращенную $16$-битовую версию ($216 = 65 \ 536$ значений), в которой представлены все современные алфавиты. В Unicode первые $128$ кодов совпадают с таблицей ASCII.
Найти эксперта


