Метод бинарного поиска
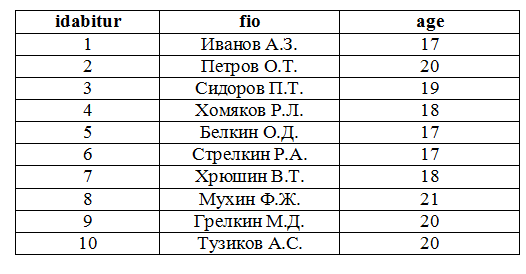
Пусть имеется таблица «abiturient», содержащая список абитуриентов. Необходимо найти в списке абитуриентов тех, кому ровно 18 лет.
Для этого нужно построить следующий запрос:
SELECT * FROM abiturient WHERE age=18;
СУБД для выполнения этого запроса должна выполнить следующие действия:
- Открыть файл, где хранится таблица «abiturient».
- Совершить перебор всех строк от начала и до конца таблицы, сравнивая значение поля age в каждой записи с числом 18. При этом будет произведено столько сравнений, сколько записей в таблице. Если в таблице 10 абитуриентов, то будет произведено 10 сравнений. Если 3000 абитуриентов, то произойдет 3000 сравнений.
Если отсортировать данные по полю age, то при 10 записях результат можно получить за 2 шага.
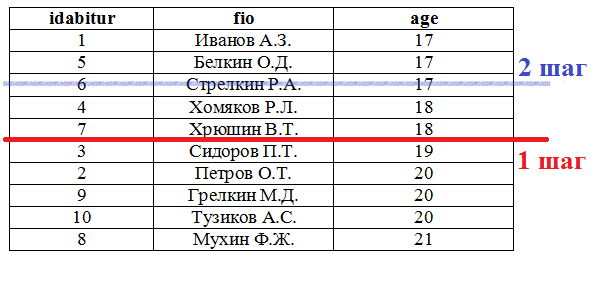
Сначала таблица делится пополам и производится сравнение с числом 18. после этого вторая половина таблицы не рассматривается вообще – все числа в ней больше 18 и нужных записей среди них нет. Первая половина таблицы делится пополам еще раз. И снова проводится сравнение. Все значения больше 17 находятся в нижней половине. Таким образом мы выделили фрагмент таблицы, где поле age принимает значения больше 17 и меньше 19. Следовательно, это и есть строки, где $age =18$.
Этот метод называется методом половинного деления или методом бинарного поиска.
Таким образом, сортировка по полю, по которому проводится отбор, позволяет применить метод бинарного поиска и выполнить запрос в несколько раз быстрее. Для таблицы с десятью записями эта экономия времени не заметна, но если число записей равно нескольким тысячам, то экономия времени будет очень существенной.
Индексирование таблиц
Индексом называется отсортированный набор значений определенного поля или группы полей.
Если поле часто используется в инструкции WHERE, то для него нужно создавать индекс. Индексы создаются либо в команде CREATE TABLE при создании таблицы, либо специальной командой CREATE INDEX, если таблица уже существует.

Например, чтобы создать индекс для поля age в рассмотренном примере, нужно выполнить команду:
CREATE INDEX age ON abiturient(age);
- Параметр длина_поля используется только для текстовых полей. Он позволяет создать индекс для части поля заданной длины. Например, упорядочивать только по первым трем символам.
- Необязательная инструкция UNIQUE устанавливает требование уникальности индекса. Это нужно в случае, если поле содержит уникальные значения. Например, уникальный индекс можно построить для поля, содержащего номер телефона. При поиске после первого нахождения нужного номера процесс прекратится, потому что индекс уникален и других таких же значений уже не будет. Это также сокращает число операций.
- Необязательная инструкция FULLTEXT может быть использована только для полей текстового типа – CHAR, VARCHAR, TEXT. Она обеспечивает полнотекстовый поиск.
Для запросов, имеющих критерии отбора по нескольким полям нужно создавать составные индексы.
Рассмотрим запрос
SELECT * FROM abiturient WHERE age=18 AND gender=’ж’;
В этом случае полезно будет создать составной индекс
CREATE INDEX age_gen ON abiturient(age, gender);
Селективность
В примере2 можно было составить индекс поменяв местами поля:
CREATE INDEX age_gen ON abiturient(gender,age);
Зависит ли скорость поиска от порядка полей в составном индексе? Да, зависит.
Допустим в таблице 1000 абитуриентов. Примерно половина из них женского пола и примерно половина мужского. В среднем около 166 абитуриентов будет приходиться на каждый возраст.
1 способ построения индекса. Если сначала провести отбор по полу, то количество записей сократится приблизительно до 500. И среди этих 500 нужно будет искать абитуриентов нужного возраста.
2 способ построения индекса. Если сначала провести отбор по возрасту, то количество записей резко сократится до 166. И уже среди 166 полученных записей нужно будет найти абитуриентов женского пола.
Если количество одинаковых значений какого-либо поля относительно невелико, то говорят, что это поле имеет высокую селективность.
Поля с высокой селективностью желательно ставить в составном индексе на первые места. Второй способ вернет результат быстрее потому, что у поля age более высокая селективность, чем у поля gender.
 Найти эксперта
Найти эксперта