




 Найти эксперта
Найти эксперта


Современные пользователи довольно часто сталкиваются с проблемой нехватки свободного пространства на жестком диске. Многие, в попытке освободить хоть немного свободного пространства, пытаются удалить с жесткого диска всю ненужную информацию. Более продвинутые пользователи используют для уменьшения объема данных особые алгоритмы сжатия. Несмотря на эффективность этого процесса, многие пользователи никогда о нем даже не слышали. Давайте же попробуем разобраться, что подразумевается под сжатием данных, какие алгоритмы для этого могут использоваться.
На сегодняшний день сжатие информации является достаточно важной процедурой, которая необходима каждому пользователю ПК. Сегодня любой пользователь может позволить себе приобрести современный накопитель данных, в котором предусмотрена возможность использования большого объема памяти. Подобные устройства, как правило, оснащаются высокоскоростными каналами для транслирования информации. Однако, стоит отметить, что с каждым годом объем необходимой пользователям информации становится все больше и больше. Всего $10$ лет назад объем стандартного видеофильма не превышал $700$ Мб. В настоящее время объем фильмов в HD-качестве может достигать нескольких десятков гигабайт.
Когда необходимо сжатие данных?
Не стоит многого ждать от процесса сжатия информации. Но все-таки встречаются ситуации, в которых сжатие информации бывает просто необходимым и крайне полезным. Рассмотрим некоторые из таких случаев.
-
Передача по электронной почте.
Очень часто бывают ситуации, когда нужно переслать большой объем данных по электронной почте. Благодаря сжатию можно существенно уменьшить размер передаваемых файлов. Особенно оценят преимущества данной процедуры те пользователи, которые используют для пересылки информации мобильные устройства.
-
Публикация данных на интернет-сайтах и порталах.
Процедура сжатия часто используется для уменьшения объема документов, используемых для публикации на различных интернет-ресурсах. Это позволяет значительно сэкономить на трафике.
-
Экономия свободного места на диске.
Когда нет возможности добавить в систему новые средства для хранения информации, можно использовать процедуру сжатия для экономии свободного пространства на диске. Бывает так, что бюджет пользователя крайне ограничен, а свободного пространства на жестком диске не хватает. Вот тут-то на помощь и приходит процедура сжатия.
Кроме перечисленных выше ситуаций, возможно еще огромное количество случаев, в которых процесс сжатия данных может оказаться очень полезным. Мы перечислили только самые распространенные.
Способы сжатия информации
Все существующие способы сжатия информации можно разделить на две основные категории. Это сжатие без потерь и сжатие с определенными потерями. Первая категория актуальна только тогда, когда есть необходимость восстановить данные с высокой точностью, не потеряв ни одного бита исходной информации. Единственный случай, в котором необходимо использовать именно этот подход, это сжатие текстовых документов.
В том случае, если нет особой необходимости в максимально точном восстановлении сжатой информации, необходимо предусмотреть возможность использования алгоритмов с определенными потерями при сжатии.
Сжатие без потери информации
Данные методы сжатия информации интересуют прежде всего, так как именно они применяются при передаче больших объемов информации по электронной почте, при выдаче выполненной работы заказчику или при создании резервных копий информации, хранящейся на компьютере. Эти методы сжатия информации не допускают потерю информации, поскольку в их основу положено лишь устранение ее избыточности, информация же имеет избыточность практически всегда, если бы последней не было, нечего было бы и сжимать.
Приведем простой пример. Русский язык включает в себя $33$ буквы, $10$ цифр и еще примерно $15$ знаков препинания и других специальных символов. Для текста, записанного только прописными русскими буквами (например как в телеграммах) вполне хватило бы $60$ разных значений. Тем не менее, каждый символ обычно кодируется байтом, содержащим, как нам известно, 8 битов, и может выражаться $256$ различными кодами. Это один из первых факторов, характеризующих избыточность. Для телеграфного текста вполне хватило бы и $6$ битов на символ.
Рассмотрим другой пример. В международной кодировке символов ASCII для кодирования любого символа выделяется одинаковое количество битов ($8$), в то время, как всем давно и хорошо известно, что наиболее часто встречающиеся символы имеет смысл кодировать меньшим количеством знаков. Так, к примеру, в азбуке Морзе буквы «Е» и «Т», которые встречаются очень часто, кодируются $1$ знаком (соответственно это точка и тире). А такие редкие буквы, как «Ю» ($• • - -$) и «Ц» ($- • - •$), кодируются $4$ знаками.
Неэффективная кодировка является вторым фактором, характеризующим избыточность. Программы, благодаря которым выполняется сжатие информации, могут вводить свою кодировку, причем она может быть разной для разных файлов, и приписывать ее к сжатому файлу в виде таблицы (словаря), из которой распаковывающая программа будет считывать информацию о том, как в данном файле закодированы те или иные символы или их группы.
Алгоритмы, в основу которых положено перекодирование информации, называются алгоритмами Хаффмана.
Алгоритм Хаффмана
В данном алгоритме сжатие информации осуществляется путем статистического кодирования или на основе словаря, который предварительно был создан. Согласно статистическому алгоритму Хаффмана каждому входному символу присваивается определенный код. При этом наиболее часто используемому символу - наиболее короткий код, а наиболее редко используемому - более длинный. В качестве примера на диаграмме приведено распределение частоты использования отдельных букв английского алфавита (рис.1). Такое распределение может быть построено и для русского языка. Таблицы кодирования создаются заранее и имеют ограниченный размер. Этот алгоритм обеспечивает наибольшее быстродействие и наименьшие задержки. Для получения высоких коэффициентов сжатия статистический метод требует больших объемов памяти.
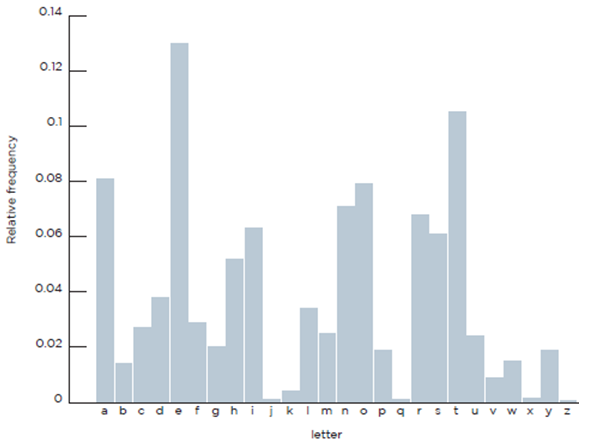
Рисунок 1. Распределение английских букв по их частоте использования
Величина сжатия определяется избыточностью обрабатываемого массива бит. Каждый из естественных языков обладает определенной избыточностью. Среди европейских языков русский имеет самый высокий уровней избыточности. Об этом можно судить по размерам русского перевода английского текста. Обычно он примерно на $30\%$ больше. Если речь идет о стихотворном тексте, избыточность может быть до $2$ раз выше.
Самая большая сложность с кодами заключается в необходимости иметь таблицы вероятностей для каждого типа сжимаемых данных. Это не представляет проблемы, если известно, что сжимается английский или русский текст. В этом случае мы просто предоставляем кодеру и декодеру подходящее для английского или русского текста кодовое дерево. В общем же случае, когда вероятность символов для входных данных неизвестна, статические коды Хаффмана работают неэффективно.
Решением этой проблемы является статистический анализ кодируемых данных, выполняемый в ходе первого прохода по данным, и составление на его основе кодового дерева. Собственно кодирование при этом выполняется вторым проходом.
Еще одним недостатком кодов является то, что минимальная длина кодового слова для них не может быть меньше единицы, тогда как энтропия сообщения вполне может составлять и $0,1$, и $0,01$ бит/букву. В этом случае код становится существенно избыточным. Проблема решается применением алгоритма к блокам символов, но тогда усложняется процедура кодирования/декодирования и значительно расширяется кодовое дерево, которое нужно в конечном итоге сохранять вместе с кодом.
Данные коды никак не учитывают взаимосвязей между символами, которые присутствуют практически в любом тексте.
Сегодня, в век информации, несмотря на то, что практически каждому пользователю доступны высокоскоростные каналы для передачи данных и носители больших объемов, вопрос сжатия данных остается актуальным. Существуют ситуации, в которых сжатие данных является просто необходимой операцией. В частности, это касается пересылки данных по электронной почте и размещения информации в Интернете.
Найти эксперта



