Индекс и индексирование
Автоматическая сортировка записей, контроль отсутствия повторяющихся записей, увеличение скорости выполнения поисковых операций в таблице выполняется для определения ключа таблицы. С целью реализации названных функций в СУБД применяется индексирование.
Индексом является средством ускорения поисковых операций записей в таблице, а значит, и других операций, которые используют поиск: операций извлечения, модификации, сортировки и т.д.
Таблица, для которой используют индекс, называется индексированной.
Индекс играет роль оглавления таблицы и его просмотр выполняется до обращения к записям таблицы. Некоторые системы, например Paradox, хранят индексы в индексных файлах, которые хранятся отдельно от табличных файлов.
На решение проблем организации физического доступа к данным влияет:
- вид содержимого записей индексного файла в поле ключа;
- тип ссылок (указателей) на запись основной таблицы, которые используются;
- метод поиска необходимых записей.
Поле ключа индексного файла может хранить значения ключевых полей индексируемой таблицы или свертку ключа (хеш-код).
Преимущества и недостатки
Преимуществом хранения хеш-кода является постоянная и достаточно малая величина (например, 2 байта) его длины, которая не зависит от длины исходящего значения ключевого поля, что существенно влияет на снижение времени поисковых операций.
Недостаток хеширования состоит в необходимости выполнения операции свертки, которая занимает определенное время, а также предупреждение возникновения коллизий (результатом свертки разных значений может быть одинаковый хеш-код).
Для создания ссылки на запись таблицы может быть использовано 3 типа адресов:
- символический (идентификатор);
- относительный;
- абсолютный (действительный).
В практическом применении чаще всего используют 2 метода поиска: бинарный (основанный на делении пополам интервала поиска) и последовательный.
Рассмотрим одноуровневую и двухуровневую схему индексирования таблиц.
При использовании одноуровневой схемы индексный файл хранит короткие записи, которые имеют 2 поля:
- хеш-кода ключа (содержимого старшего ключа) адресуемого блока;
- адреса начала адресуемого блока (рисунок 1).
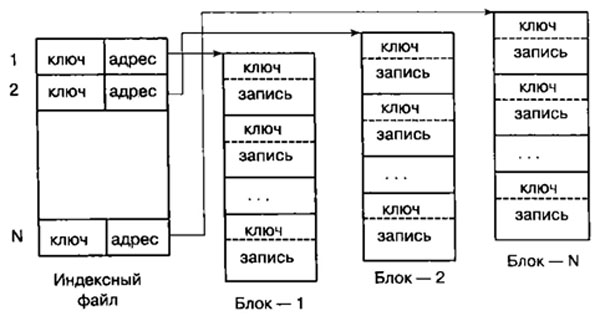
Записи в каждом блоке размещаются по возрастанию значения свертки или ключа. Ключ каждого блока последней записи является старшим его ключом.
Основной недостаток одноуровневой схемы состоит в хранении ключей (сверток) записей вместе с записями, что приводит к длительному поиску записей вследствие большой длины просмотра.
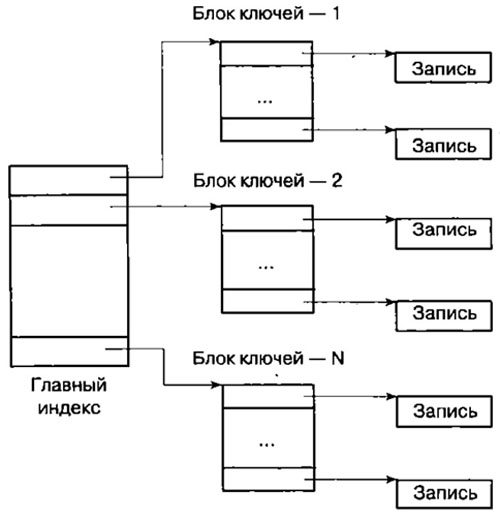
Двухуровневая схема иногда является более рациональной, т.к. ключи (свертки) записей отделяются от содержимого записей (рисунок 2).
При работе с таблицами БД для создания индекса пользователем указывается поле таблицы, требующее индексации. Во многих СУБД выполняется автоматическая индексация ключевых полей таблицы.
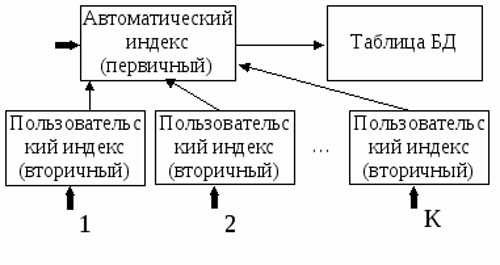
Индексные файлы, которые создаются по ключевым полям таблицы, зачастую называют файлами первичных индексов.
Индексы, которые создает пользователь для не ключевых полей, называются вторичными (или пользовательскими) индексами.
Индексные файлы, которые создаются для поддержки вторичных индексов таблицы, принято называть файлами вторичных индексов.
Связь вторичного индекса и элементов данных БД может устанавливаться разными способами. Например, вторичный индекс используется как вход для получения первичного ключа, по которому выполняется поиск нужных записей с использованием первичного индекса (рисунок 3).
Главной причиной повышения скорости выполнения разных операций в индексированных таблицах является выполнение основной части работы с небольшими индексными файлами.
Повышение производительности работы достигается с наибольшим эффектом при использовании больших таблиц.
 Найти эксперта
Найти эксперта